MASKED ACOUSTIC UNIT FOR MISPRONUNCIATION DETECTION AND CORRECTION
Abstract
Computer-Assisted Pronunciation Training (CAPT) plays an important role in language learning. Conventional ASR-based CAPT methods require expensive annotation of the ground truth pronunciation for the supervised training. Meanwhile, certain undefined non-native phonemes cannot be correctly classified into standard phonemes, making the annotation process challenging and subjective. On the other hand, ASR-based CAPT methods only give the learner textbased feedback about the mispronunciation, but cannot teach the learner how to pronounce the sentence correctly. To solve these limitations, we propose to use the acoustic unit (AU) as the intermediary feature for both mispronunciation detection and correction. The proposed method uses the masked AU sequence and the target phonemes to detect the error AU and then corrects it. This method can give the learner speechbased self-imitating feedback, making our CAPT powerful for education.
Introduction
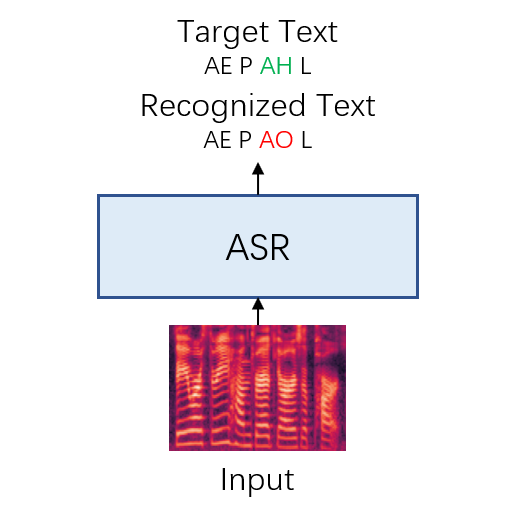
First, let's view the ASR-based CAPT model.
Fig 1: Structure of the ASR-based model.
This kind of models recognize the input spectrum and align the text with the target one to find the mispronunciation. However, it assumes that the spectrum can be classified into these defined standard phonemes. Meanwhile, it can only offer a text-based feedback about where the misprounciation is but cannot teach the learner the correction pronunciation.
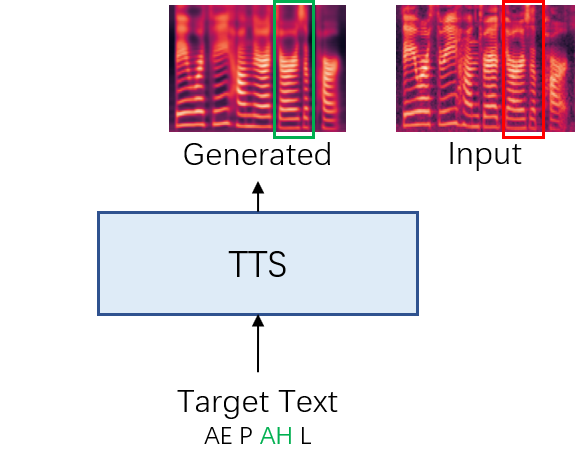
How can we make the CAPT system to speak just like a teacher? Naturally, we can think of text-to-speech (TTS) technologies. By generating the standard pronunciation, we can learn how the text is correctly pronounced. We can also compare the generated spectrum and the input one to detect the error.
Fig 2: Structure of the Comparison-based model.
However, spectrum-based comparison may not be robust due to style or speaker variation. Can we use a more robust feature for both detection and speech-based feedback for correction?
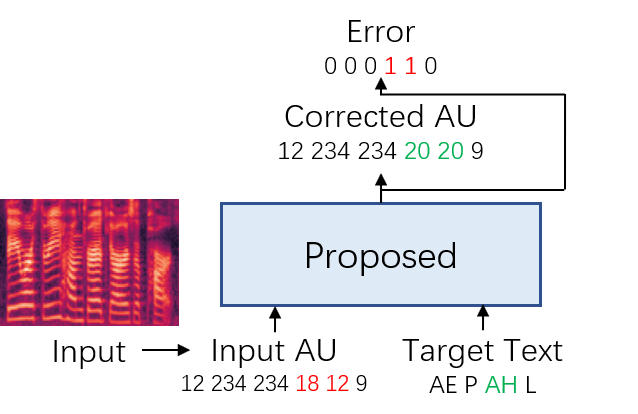
In this paper, we use the acoustic unit (AU) as the intermediary feature for both misprounciation detection and correction.
Fig 3: Structure of the proposed model.
About acoustic unit
Simply speaking, we can view AUs as fake phonemes. They contains the linguistic information of the speech (but removes the speaker's style). To demonstrate this characteristic, we can convert the speech into AUs and then resynthesis it using any other speaker embedding. The synthesised speech keeps the content but changes the speaking style.
Note
For the following audio sample groups, we use the first speaker's voice (S0) to resynthesis the other speeches (S1 and S2).
The upper row is the raw speech and the lower row is the synthesised speech.
Group 1
S0
S1
S2
Group 2
S0
S1
S2
Group 3
S0
S1
S2
Group 4
S0
S1
S2
Audio samples
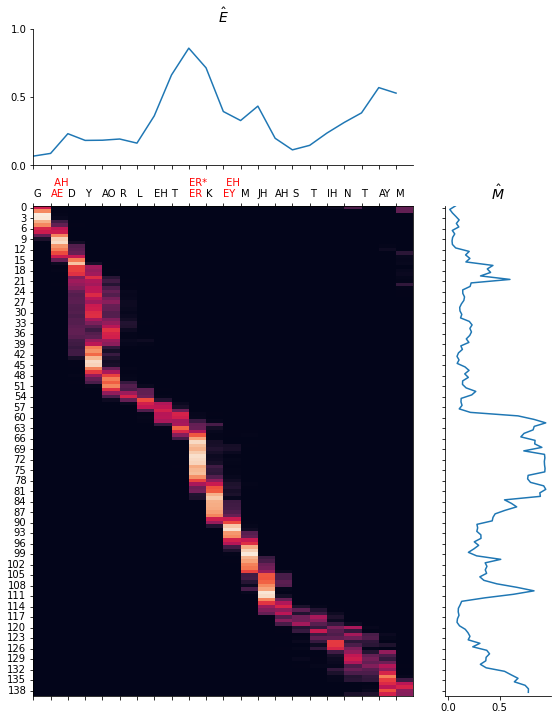
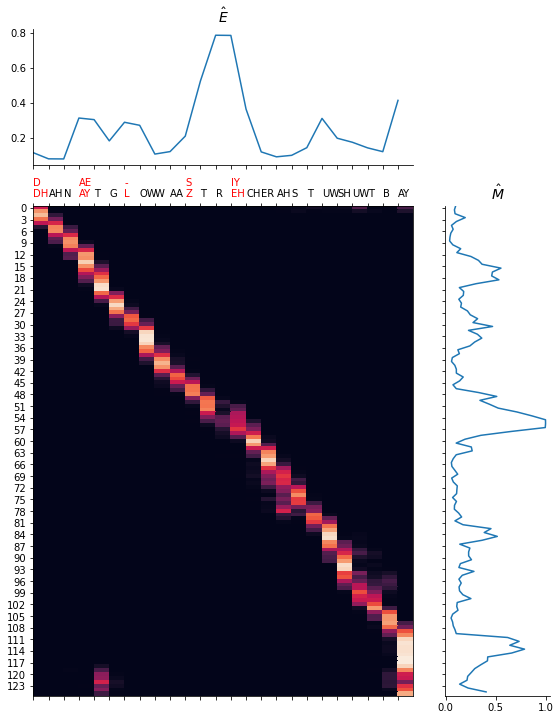
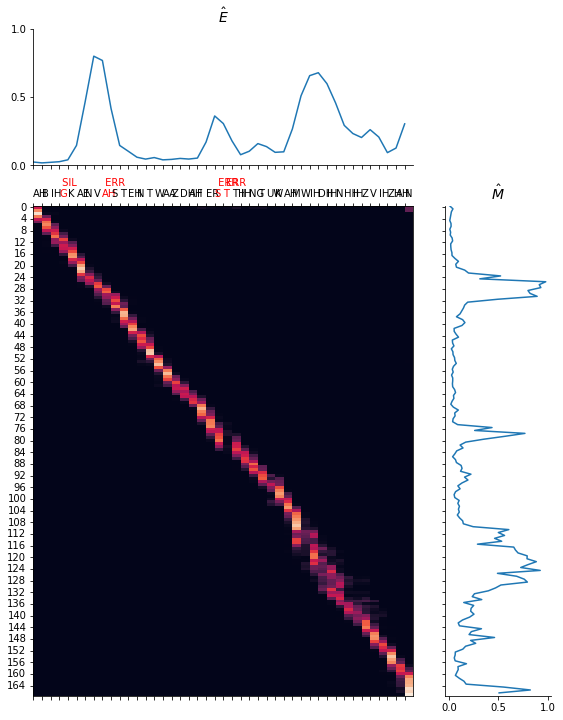
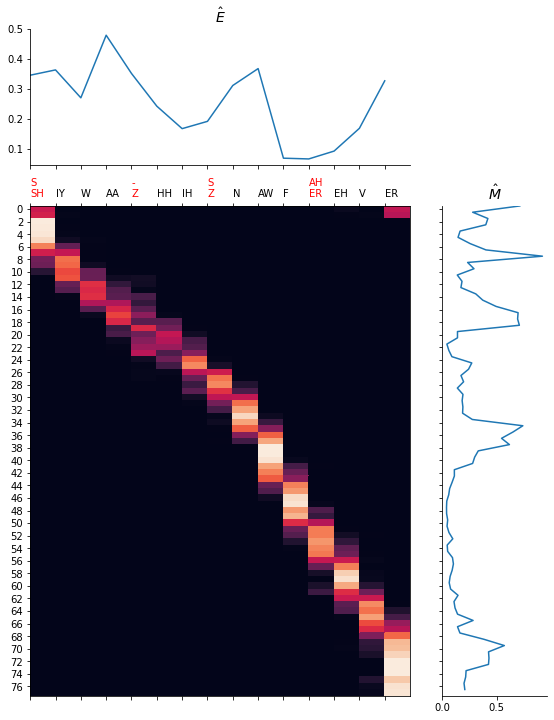
We give several samples to show the performance. Note that we force the duration of each phoneme to be the same as the original one for Fastspeech2 so that the error can be calculated. However, the force alignment obtained from the teacher (trained on L1 dataset) may be wrong for L2-Arctic. Thus, certain sample may produce unnatural pronunciation.
In general, without the style, the generated speech is more natural. However, it also becomes dull. In our survey, more volunteers prefer the CAPT system that can offer the stylized feedback because the education process is more personalized.
NCC_arctic_a0099
NCC_arctic_a0099: A maddening joy pounded in his brain.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
YBAA_arctic_a0008
YBAA_arctic_a0008: Gad your letter came just in time.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
BWC_arctic_a0089
BWC_arctic_a0089: The night glow was treacherous to shoot by.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
YKWK_arctic_a0095
YKWK_arctic_a0095: A big canvas tent was the first thing to come within his vision.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
THV_arctic_a0130
THV_arctic_a0130: She was his now forever.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
About annotation
We should also note that the annotation of the misprounciation is difficult and subjective. Certain annotations differs from the judgement of the volunteers.
HKK_arctic_a0006
In this sample, the final "forever" seems abnormal as the speaker is laughing. However, it can be subjective to mark it as a mispronunciation or not.
HKK_arctic_a0006: God bless 'em I hope I'll go on seeing them forever.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
YBAA_arctic_a0003
The stress of "twentieth" is incorrect, but not labelled as a mispronunciation.
YBAA_arctic_a0003: For the twentieth time that evening the two men shook hands.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
HKK_arctic_b0225
"President" here sounds more like "Presidernt", but is not labelled as a mispronunciation in the annotation.
HKK_arctic_b0225: The President of the United States was his friend.
Raw
Raw AU Decoded
Google TTS
Corrected
TTS w/ Style
TTS w/o Style
HKK_arctic_a0008
"Came" sounds like "canme" but is not labelled as a mispronunciation in the annotation.
HKK_arctic_a0008: Gad your letter came just in time.